
cpu流水线技术,cpu流水线过长
- 百科知识
- 2年前
- 46
- 更新:2022-09-20 07:27:09
今天给各位分享关于“cpu流水线技术”的核心内容以及“cpu流水线过长”的相关知识,希望对各位有所帮助。
Cpu管道(cpu管道太长)
由半导体产业观察(ID:icbank)从《自然》编辑而来,谢谢。
摘要

大约50年前,英特尔创造了世界上第一个商业化生产的微处理器,一个普通的4位CPU(*处理器)和2300个晶体管,这些微处理器采用10μm工艺技术在硅中制造,只能进行简单的算术计算。自从这一突破以来,技术一直在发展,变得越来越复杂。目前最先进的64位硅微处理器已经有300亿个晶体管(比如7 nm工艺技术制造的AWS Gravity on 2微处理器)。
微处理器现在已经渗透到我们的文化中,并成为一种元发明——也就是说,它是一种能够实现其他发明的工具。最近的一项发明使得在创纪录的时间内分析新冠肺炎疫苗开发所需的大数据成为可能。
本文报道了一种采用金属氧化物薄膜晶体管技术在柔性衬底上开发的32位Arm微处理器。与主流半导体行业不同,柔性电子产品通过超薄的外形、集成化、极低的成本和量产的潜力,与日常生活用品无缝融合。PlasticARM是将数十亿个低成本超薄微处理器嵌入日常产品的先驱。
与传统的半导体器件不同,柔性电子器件构建在诸如纸、塑料或金属箔的基底上,并且使用诸如有机或金属氧化物或非晶硅的活性薄膜半导体材料。与晶体硅相比,它们具有许多优点,包括薄、均匀和低制造成本。柔性衬底上薄膜晶体管的制造成本远低于晶体硅片上金属氧化物半导体场效应晶体管的制造成本。
TFT技术的目的不是取代硅。随着这两项技术的不断发展,硅很可能会保持其在性能、密度和功率效率方面的优势。然而,薄膜晶体管使电子产品具有硅无法达到的新颖外形和成本点,从而大大扩展了潜在的应用范围。
微处理器是每一个电子设备的核心,包括智能手机、平板电脑、笔记本电脑、路由器、服务器、汽车,以及最近组成物联网的智能物品。虽然传统芯片技术已经在地球上的每一个“智能”设备中嵌入了至少一个微处理器,但它面临着让日常物品变得更智能的关键挑战,比如瓶子、食品包装、服装、可穿戴贴片、绷带等等。成本是阻碍传统硅技术在这些日常用品中可行性的最重要因素。尽管芯片制造的规模经济可以大大降低单位成本,但微处理器的单位成本仍然令人望而却步。此外,硅片本身并不是很薄,柔性和一致性,这是在这些日常用品中嵌入电子产品非常理想的特性。
另一方面,柔性电子产品确实提供了这些令人满意的特征。在过去的20年里,柔性电子产品已经发展到提供成熟的低成本、薄、柔性和兼容的设备,包括传感器、存储器、电池、发光二极管、能量收集器、近场通信/射频识别和印刷电路,如天线。这些是构建任何智能集成电子设备的基本电子组件。缺少的部分是灵活的微处理器。目前还没有可行的柔性微处理器。主要原因是为了执行有意义的计算,需要在柔性衬底上集成相对大量的薄膜晶体管,这在以前的薄膜晶体管技术中是不可能的。在这项技术中,大规模集成之前需要一定程度的技术成熟度。
中间的方法是将硅基微处理器芯片集成在柔性衬底上,也称为混合集成,将硅片减薄,将芯片集成在柔性衬底上。虽然薄硅片集成提供了短期解决方案,但这种方法仍然依赖于传统的高成本制造工艺。因此,在未来10年甚至更长时间内生产数十亿件日常智能商品并不是一个可行的长期解决方案。
我们的方法是利用柔性电子制造技术开发微处理器,也称为柔性加工引擎。我们使用柔性电子技术在聚酰亚胺衬底上构建了一个局部柔性微处理器。金属氧化物薄膜晶体管具有低成本,并且可以减小到大规模集成所需的较小几何尺寸。
早期原生柔性处理器工作是基于使用低温多晶硅TFT技术开发8位CPU,制造成本高,横向扩展性差。最近,二维材料晶体管被用于开发处理器,例如使用二硫化钼(MoS 2)晶体管的1位CPU 13和使用互补碳纳米管晶体管的16位RISC-V CPU。然而,这两个任务是在传统的硅晶片而不是柔性衬底上执行的。
首次尝试构建基于金属氧化物TFT的处理元件是一个8位算术逻辑单元,它是CPU的一部分,并与聚酰亚胺制成的印刷可编程ROM相结合。最近,Ozer等人提出了一种在金属氧化物薄膜晶体管中具有固有灵活性的特殊机器学习硬件。虽然机器学习硬件拥有最复杂的柔性集成电路(FlexIC),由1400个金属氧化物薄膜晶体管组成,但FlexIC不是微处理器。可编程处理器方法比机器学习硬件更通用,支持丰富的指令集,可用于编程从控制代码到数据密集型应用(包括机器学习算法)的各种应用。
原生柔性微处理器主要有三个组成部分:(1)32位CPU,(2) 32位处理器,包括CPU和CPU外设,(3)片上系统(SoC),包括处理器、存储器和总线接口,均由柔性衬底上的金属氧化物TFT制成。原生灵活的32位处理器来自支持Armv6-M架构和现有软件开发工具链(如编译器、调试器、连接器、集成开发环境等)的Arm Cortex-M0+处理器(一组80多条指令)。).整个灵活的SoC叫做PlasticARM,它可以从内部内存运行程序。PlasticARM包含18,334个NAND2等效栅极,这使其成为由柔性衬底上的金属氧化物薄膜晶体管制造的最复杂的FlexIC(比以前的集成电路至少复杂12倍)。
塑料手臂系统架构
PlasticARM的芯片架构如下图所示。它是由32位Arm Cortex-M0+处理器产品衍生而来的一种SoC,包括32位处理器、内存、系统互连结构以及接口块和外部总线接口。
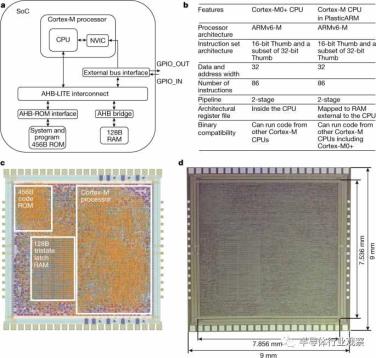
PlasticARM架构和特性
一、SoC架构,展示内部结构、处理器和系统外设。该处理器由一个32位Arm Cortex-M CPU和一个嵌套矢量中断控制器(NVIC)组成,它们通过互连结构(AHB-LITE)连接到其内存。最后,外部总线接口提供通用输入输出(GPIO)接口,用于与测试框架进行片外通信。
b、与Arm Cortex-M0+CPU相比,PlasticARM使用的CPU的特点。两个CPU都完全支持Armv6-M架构、32位地址和数据能力,以及来自整个16位Thumb和32位Thumb指令集架构子集的86条指令。CPU微架构有两级流水线。寄存器在Cortex-M0+的CPU中,但在PlasticARM中,寄存器被移动到SoC中基于锁存器的RAM中,以节省Cortex-M的CPU区域。最后,两个CPU相互二进制兼容,并与同一架构家族中的其他CPU兼容。
c、PlasticARM的模具布局,代表Cortex-M处理器、ROM、RAM等白盒中的关键块。
D.PlasticARM的模具显微照片,显示了模具和型芯区域的尺寸。
该处理器完全支持Armv6-M指令集架构,这意味着为Cortex-M0+处理器生成的代码也将在其派生处理器上运行。包括处理器*处理器和嵌套的矢量中断控制器(NVIC),该控制器与*处理器紧密耦合以处理来自外部设备的中断。
SoC的其余部分由内存(ROM/RAM)、AHB-LITE互连结构(高级高性能总线(AHB)规范的子集)、用于将内存连接到处理器的接口逻辑以及用于控制两个通用输入输出(GPIO)引脚之间片外通信的外部总线接口组成。ROM包含456字节的系统代码和测试程序,并已实现为组合逻辑。28字节的内存已经实现为基于锁存器的寄存器文件,主要用作堆栈。
上面的图B显示了在PlasticARM中使用的Cortex-M和Arm Cortex-M0+之间的比较。虽然PlasticARM中的Cortex-M处理器不是标准产品,但它实现了Armv6-M架构,该架构支持16位Thumb指令集架构和32位Thumb指令集架构的子集,因此它与同一架构家族中的所有Cortex-M处理器(包括Cortex-M0+)二进制兼容。
PlasticARM中Cortex-M和Cortex-M0+的关键区别在于,我们将SoC中RAM的特定部分分配给CPU寄存器(约64字节),并在PlasticARM中将它们从CPU移动到Cortex-M中的RAM,而Cortex-M0+中的寄存器则保留在其CPU中。通过取消CPU中的寄存器,使用现有的RAM作为寄存器空室,以寄存器访问速度慢为代价,大大减少了CPU面积(约3倍)。
结果
PlasticARM采用务实的0.8μm工艺和工业标准芯片实现工具。为了实现PlasticARM FlexIC,我们开发了工艺设计工具包、标准单元库和器件/电路仿真。上面的图C展示了FlexIC的布局,其中Cortex-M处理器、RAM和ROM是分开的。实现的细节可以在方法中找到。
PlasticARM由商用“盒中制造”生产线FlexLogIC制造,其芯片显微照片如上图d所示,该工艺采用基于IGZO的N型金属氧化物TFT技术,在直径200 mm的聚酰亚胺晶圆上生成FlexIC设计,IGZO TFT电路采用传统半导体加工设备制作,适用于在厚度小于30微米的柔性(聚酰亚胺)基板上生产器件..沟道长度为0.8μm,最小电源电压为3 V..
N型金属氧化物薄膜技术的设计面临许多相同的挑战,这些挑战影响了20世纪70年代和80年代初第一代硅(负沟道金属氧化物半导体,NMOS)技术的复杂性和产量,特别是低噪声容限、高功耗和巨大的工艺变化。制造方法的细节可以在“方法”中找到。
我们报告了一种功能齐全的弹性塑料臂,这已经通过在制造前运行三个预编程(硬连线)到只读存储器中的测试程序得到了证明。虽然测试程序是从rom执行的,但这不是系统的要求。它简化了PlasticARM的测试设置。当前的只读存储器实现不允许在制造后改变或更新程序代码,尽管这在未来的实现中是可能的(例如,通过可编程只读存储器)。
测试程序的编写方式是,指令执行CPU内部的所有功能单元,如算术逻辑单元、加载/存储单元和分支单元,并使用armcc编译器编译,CPU标志设置为cortex-m0plus。测试程序的流程图和详细描述如图2所示。当每个测试程序完成其执行时,测试程序的结果通过输出GPIO引脚关闭芯片传输到测试帧。
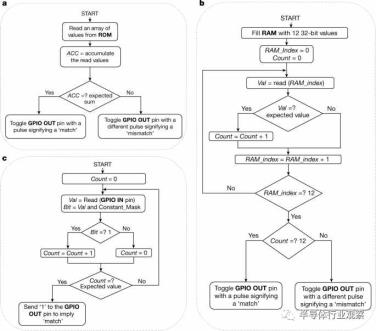
测试程序
一个简单的累加程序从只读存储器中读取值并相加。如果总和与预期值匹配,将向测试仪读取的GPIO输出引脚发送确认信号。该测试使用加载、添加、比较和分支指令。
b、一组32位整数值立即写入RAM,并在检查读取值和期望值的同时回读。如果所有写入的值都被正确读取,一个确认信号将被发送到GPIO输出引脚。该测试使用加载、存储、添加、移位、逻辑、比较和分支指令。
c、通过GPIO输入引脚从测试仪连续读取一个值。该值被一个常数值屏蔽。如果屏蔽结果为1,计数器将递增。如果为0,计数器复位。如果计数器值等于预期值,将向GPIO输出引脚发送确认信号。该测试使用加载、存储、添加、逻辑、比较和分支指令。斜体表示测试程序中的变量;粗体和大写的术语是pin和memory。
众所周知,IGZO TFT可以弯曲到3毫米的曲率半径而不损坏,务实也通过反复弯曲自己的电路到这个曲率半径验证了这一点。然而,所有的塑料臂测量都是在室温下进行的,柔性晶片保留在其玻璃载体上,使用位于ARM有限公司的标准晶片测试设备。塑料臂的测量结果及其模拟结果得到了验证。在该方法中可以找到模拟的设置、结果及其验证的细节。
表1给出了PlasticARM的实现和实测电路特性,并与之前金属氧化物薄膜晶体管构建的最佳天然柔性集成电路进行了比较。PlasticARM的面积为59.2 mm 2(无焊盘),包含56,340个器件(N型TFT加电阻)或18,334个NAND2等效门,比之前最好的集成电路(即二元神经网络(BNN)FlexIC)至少高出12倍。微处理器的时钟频率高达29 kHz,功耗仅为21 mW,主要为(> 99%)静态功耗,其中处理器占45%,存储器占33%,外设占22%。SoC采用28个引脚,包括时钟、复位、GPIO、电源等调试引脚。本设计中没有使用特殊的静电放电缓解技术。相反,所有输入均包含140pF电容,而所有输出均由带有源上拉晶体管的输出驱动器驱动。
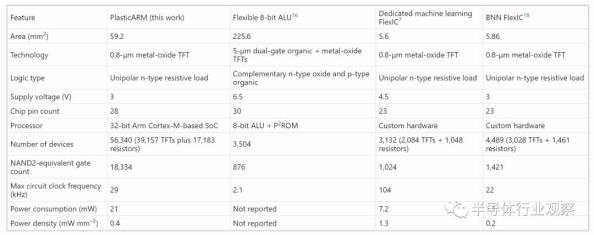
表1:由金属氧化物薄膜晶体管构成的柔性集成电路的优点
任何阻性负载技术的一个关键挑战是功耗。我们预计,正在开发的低功耗单元库将支持更高的复杂性,最多可达100,000个门。迁移到超过1,000,000个栅极可能需要互补金属氧化物半导体(CMOS)技术。
结论
我们报道了一种采用0.8μm金属氧化物薄膜晶体管技术制造的柔性32位微处理器塑料臂。我们已经演示了一个片上系统的功能,它有一个32位Arm处理器制作在一个柔性衬底上。它可以利用现有的软件/工具支持(如编译器),因为它与Armv6-M架构中的Arm Cortex-M类处理器兼容,所以不需要开发软件工具链。最后,据我们所知,它是由金属氧化物tft制成的最复杂的柔性集成电路,包含18000多个栅极,比以前最好的集成电路至少高12倍。
我们假设PlasticARM将率先开发一个低成本、完全灵活的智能集成系统,这将使“万物互联”成为可能,包括在未来十年将超过一万亿个无生命物体集成到数字世界中。为日常生活用品提供超薄、兼容、低成本、固有灵活性的微处理器,将带来创新,从而带来各种研究和商业机会。
方法
执行
为了充分利用现代集成电路设计过程提供的高度自动化和快速周转的实现和验证,我们开发了一个小型标准单元库。标准单元库是预先验证的小型构件的集合。使用复杂的电子设计自动化工具,如合成、布局和布线,可以快速轻松地构建更大、更复杂的设计。
在实现标准单元库之前,进行了一些初步的研究,以确定在目标技术的限制下最适合该库的标准单元架构。单元架构是库中每个单元共有的一组特征,例如单元高度、电源板尺寸、布线网格等。,允许细胞以标准方式咬合在一起,形成更大的结构。这些共同特征主要由制造过程的设计规则控制,但也受到最终设计的性能和面积要求的影响。
一旦建立了单元架构,下一步就是确定单元库的内容,不仅要考虑各种逻辑函数,还要确定每个逻辑函数的驱动强度变量的数量。由于每个标准单元的设计、实现和表征都涉及繁重的工作量,因此决定使用一个小的原型库进行一些实验,然后根据需要扩展该库。为了评估这种小型原型标准单元库的性能,实现、制造和测试了一些简单的代表性电路(如环形振荡器、计数器和移位阵列)。
我们从1.0-微米设计规则转移到新的FlexIC 0.8-微米设计规则,以减少面积并增加产量。这意味着库中的每个单元都用更小的晶体管重新绘制,我们也借此机会更改了标准单元架构,以包括MT1 (Metal Tracking 1)引脚,这样路由器就可以更轻松地连接单元。材料的改进(更高的薄层电阻,电阻系数)也使电阻的尺寸减小了3倍。
晶体管和电阻器尺寸的显著减小使大多数单元的面积减少了约50%(见扩展数据图1),这又通过减小设计的整体尺寸提高了制造成品率。然而,由于仍然存在制造成品率问题,我们可以通过改变标准单元架构来进一步缓解这些问题,因此我们再次重新绘制了库。这一次,我们将重点放在可以提高最终设计整体成品率的方面,例如包括冗余过孔和触点、减少源漏多边形中的顶点数量(如果可能)以及将堆叠晶体管的尺寸保持在最小。此外,我们恢复到较低的薄层电阻,以改善工艺扩展,但我们可以通过使用较窄的电阻来节省面积。为了提高逻辑综合的整体质量,库中增加了许多复杂的AND-OR-invent和OR-AND-invent逻辑门以及一些驱动强度较高的简单逻辑门,如NAND2_X2和NOR2_X2。
flex过程是一个NMOS过程,因此它依赖于阻性负载将电池输出拉至电源以驱动FlexLogIC 1。因此,单位输出的上升时间比下降时间慢得多,这种不对称会影响性能,尤其是对于重载网络。为了改善关键网络(如时钟)的时序,我们增加了一个带有源晶体管上拉的缓冲器。尽管这些有源上拉器件增加了少量面积,但它们确实具有降低静态功耗的额外优势。具有上拉电阻和有源晶体管上拉的缓冲器的布局和模拟传输特性如图2所示。
这种简单的标准单元库被成功地用作目标技术,并使用基于行业标准电子设计自动化工具的典型IC设计过程来实现PlasticARM SoC。扩展数据表1显示了标准单元库的内容和单元使用信息。
由于我们还没有专用的静态随机存取存储器FlexIC,所以我们小心翼翼地将一些修改后的标准单元放在平铺阵列中,并通过相邻的连接形成一个32×32位的存储器(这个块可以在图1c的芯片中布局)。
Flex技术(参见扩展数据表2)有四个可布线的金属层,其中只有下面两层用于标准单元。这使得顶部的两个金属层可以用于标准电池之间的互连,然后可以在相邻电池的顶部布线,从而大大提高了整体网格密度,约为每平方毫米300个网格。
制造
工艺参数和薄膜晶体管参数的统计变化总结在扩展数据表2中。FlexLogIC是一种专有的200 mm晶圆半导体制造工艺,可创建金属氧化物薄膜晶体管和电阻的图案层,并根据FlexIC设计在柔性聚酰亚胺衬底上沉积四层可布线(无金)金属层。FlexIC设计的重复示例通过运行多个薄膜材料沉积、图案化和蚀刻序列来实现。为了便于操作并允许使用工业标准工艺工具和实现亚微米图案化特征(低至0.8μm),柔性聚酰亚胺衬底在生产开始时被旋涂在玻璃上。该工艺已经过优化,以确保在20毫米的横向距离内厚度变化基本上小于3%。材料沉积是通过物理气相沉积、原子层沉积和溶液处理(如旋涂)的结合来实现的。衬底加工条件已经被仔细优化,以最小化薄膜应力和衬底弯曲。通过使用光刻5x步进机工具实现特征图案化,该工具在200 mm直径的晶片上成像重复透镜的多个实例。每个透镜都单独聚焦,这进一步补偿了旋涂膜中的任何厚度变化。使用过程控制监控结构进行技术测量。通过使用光刻5x步进机工具实现特征图案化,该工具在200 mm直径的晶片上成像重复透镜的多个实例。每个透镜都单独聚焦,这进一步补偿了旋涂膜中的任何厚度变化。使用过程控制监控结构进行技术测量。通过使用光刻5x步进机工具实现特征图案化,该工具在200 mm直径的晶片上成像重复透镜的多个实例。每个透镜都单独聚焦,这进一步补偿了旋涂膜中的任何厚度变化。使用过程控制监控结构进行技术测量。
模拟、测试和验证
我们使用测试测量设置捕捉功能性PlasticARM FlexIC的时序特性,并将测量结果与其寄存器传输电平(RTL)的仿真结果进行比较,以验证该功能。
RTL模拟如图3所示。它首先将复位输入设置为“0”,将塑料臂复位到已知状态。然后复位设置为“1”,处理器从复位状态释放,从只读存储器开始执行代码。首先,GPIO[0]输出引脚切换一次,然后进行三次测试,如图2所示。在第一次测试中,从只读存储器中读取数据并将其添加到累加器中,并与期望值进行比较(见图2a)。如果值匹配,向GPIO[0]发送两个脉冲的短脉冲,如图3a的扩展数据所示。如果值不同,扩展数据图3b中GPIO[0]上脉冲的周期总和和空之比将增加。在第二个测试中(图2b),数据被写入内存,读回并比较。如果数据在从随机存取存储器写入或读取时没有损坏,一个3脉冲的短脉冲被发送到GPIO[0],如图3a中的扩展数据所示。如果数据损坏,GPIO[0]上脉冲的周期和将像以前一样增加。在最终测试中(图2c),处理器进入无限循环,并测量GPIO输入引脚[1]上‘1’的应用时间。如果GPIO[1]保持在“1”而没有任何故障,则GPIO[0]从“0”更改为“1”。PlasticARM的时钟频率为20khz。因为它不使用任何定时器,所以在软件中选择一个值来指示GPIO[1]信号在20khz下保持在“1”大约1秒钟。在图3a的扩展数据的模拟中,该值对应于20,459个时钟周期,并且在20 kHz产生1.02295 s。
制造完成后,塑料臂在晶片探针台上进行测试,同时仍然连接到玻璃载体。包括时钟信号在内的输入信号由Xilinx的ZC702 FPGA评估板从外部产生。输入输出信号全部由Saleae Logic Pro 16逻辑分析仪采集。测量是在3伏和4.5伏不同的时钟频率下进行的。扩展数据图4显示了电源设置为3伏、时钟频率为20千赫的实验。ZC 702的输入/输出电压将输入和输出限制在2.5 V。扩展数据图4a中显示了测量的数据波形,它与扩展数据图3a中所有三个测试的RTL模拟中的波形相匹配。PlasticARM在3 V时可以达到29千赫,在4.5 V时可以达到40千赫。
数据可用性
测试和验证中产生的波形数据可根据需要从相应作者处获得。
代码可用性
可从相应的作者处获得三个用于验证PlasticARM测试程序的代码。
★点击文末【阅读原文】查看本文原文链接!
*免责声明:本文由作者原创。文章的内容是作者个人的看法。转载《半导体行业观察》只是为了传达一种不同的观点,并不代表《半导体行业观察》同意或支持这种观点。如有异议,请联系半导体行业观察。
今天是半导体产业观察为大家分享的第2744期内容。请注意。
晶圆|集成电路|设备|汽车芯片|存储|MLCC|英伟达|模拟芯片
原创链接!
以上内容就是关于cpu流水线技术和cpu流水线过长的精彩内容,是由网络编辑之家小编整理编辑的,如果对您有帮助欢迎收藏转发...
本文由 @Jack 于2022-09-20发布在 网络编辑之家,如有疑问,请联系我们。
作者信息
热门文章

活性炭口罩可以用多久
2024-06-27中华美食版生僻字歌词
2024-06-26键盘锁了怎么解开
2024-06-26蒸包子和面配方
2024-06-26f开头的跟环保有关的单词
2024-06-29如何破解手机锁屏数字密码
2024-06-29长沙南门口小吃街几点去合适
2024-06-29埭美村在哪里
2024-06-29